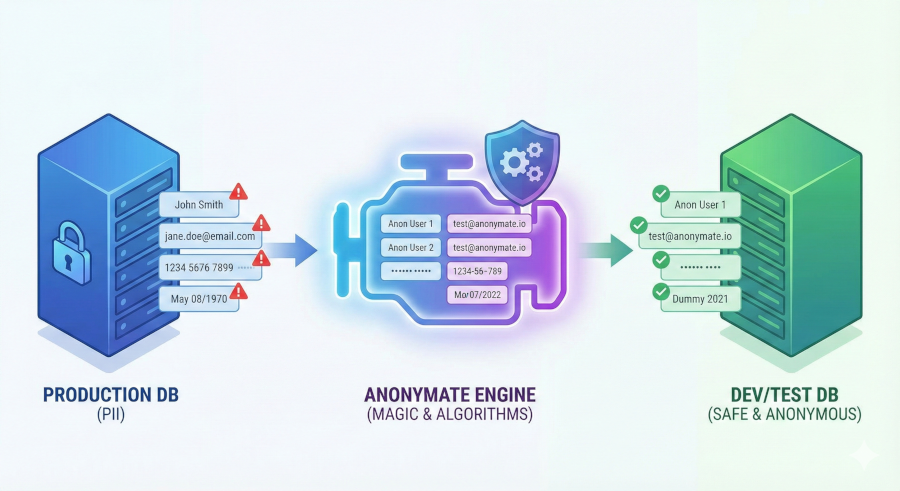
Your development is as fast as your access to safe data.
Huge fines for GDPR violations
Using production data on "dev" environments is asking for trouble. One leak can cost millions and destroy your reputation.
Unrealistic test data = Bugs in production
Teams using "John Doe" or test@test.com can't catch edge-case bugs. Debugging on production is a nightmare.
Manual scripts are a development bottleneck
Maintaining scripts is time-consuming, error-prone, and never gives you certainty. Your team should be building a product, not "cleaning" data.
Anonymate: Realistic data. Zero risk.
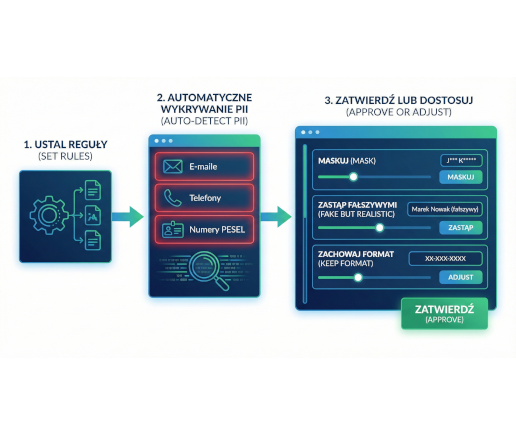
Manual anonymization is a thing of the past. It only takes 3 steps to speed up development and ensure data security.

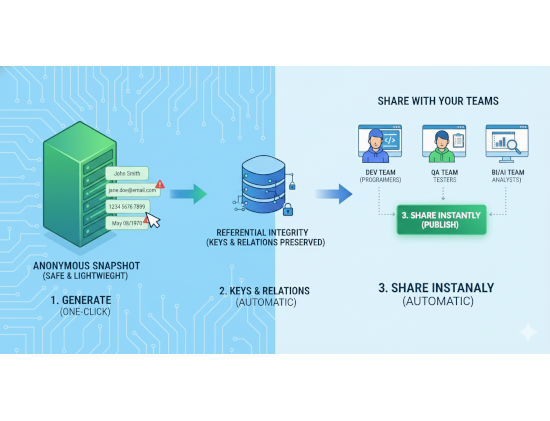
Designed for Business and Technology Leaders
Full Compliance
Sleep soundly. Anonymate guarantees that no PII data leaves production. Full compliance with GDPR, CCPA, HIPAA.
Data Consistency
No more FOREIGN KEY errors. Our engine understands your schema and maintains referential integrity.
Innovation Acceleration
Shorten "idea -> deployment" cycles by weeks. Your teams can test new features on realistic data immediately.
CI/CD Integration
Fully supported API. Plug the generation of fresh, anonymous data into your pipeline (e.g., GitLab, Jenkins, GitHub Actions).
Brand Reputation Protection
Avoid the PR nightmare of a development or test data leak.
Scalability and Performance
Whether you have 1 GB or 10 TB of data. Our system can generate data subsets so that devs don't have to download the entire database.
Unlock Data for AI/BI
Let Data Science teams train models on secure but structurally identical data.
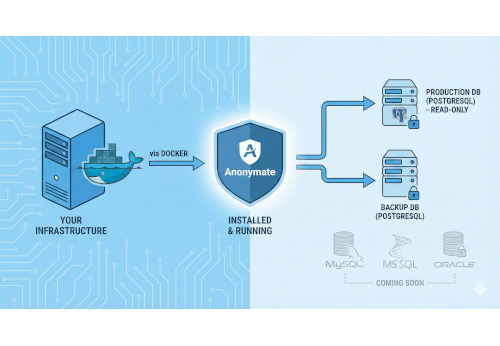
Deployment Choice (On-prem / Cloud)
Deploy in your infrastructure (on-premise) for full control or as a secure SaaS. You choose.
Unlock these scenarios – today.
Use Anonymate in development, sales, or analytics.
Fast Development & QA
Give every developer their own secure "sandbox" with realistic data in minutes.
Effective Sales Demos
Present your product with impressive, realistic data, not empty accounts or "Lorem Ipsum".
Debugging Production Errors
Replicate a production bug by anonymizing the exact piece of data that causes it, without exposing customer PII.
Training AI/ML Models
Train your algorithms on rich, structurally correct data without the slightest risk of privacy breaches.
Don't risk it. Don't slow down. Be the first.
Manual anonymization is a thing of the past. Using production data is asking for trouble.
Sign up for the Anonymate waiting list and receive an invitation to the private beta.